

-


大数据云计算
站-
热门城市 全国站>
-
其他省市
-
-

 15692118659
15692118659
 小职
2021-08-18
来源 :
阅读 2170
评论 0
小职
2021-08-18
来源 :
阅读 2170
评论 0
摘要:本文主要介绍了大数据入门到精通之Hive之分区表与实战,通过具体的内容向大家展现,希望对大家大数据的学习有所帮助。
本文主要介绍了大数据入门到精通之Hive之分区表与实战,通过具体的内容向大家展现,希望对大家大数据的学习有所帮助。

1:分区表的原因
如果hive当中所有的数据都存入到一个文件夹下面,那么在使用MR计算程序的时候,读取一整个目录下面的所有文件来进行计算,就会变得特别慢,因为数据量太大了
实际工作当中一般都是计算前一天的数据,所以我们只需要将前一天的数据挑出来放到一个文件夹下面即可,专门去计算前一天的数据。
这样就可以使用hive当中的分区表,通过分文件夹的形式,将每一天的数据都分成为一个文件夹,然后我们计算数据的时候,通过指定前一天的文件夹即可只计算前一天的数据。
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。
2:分区表的存储结构
在文件系统上建立文件夹,把表的数据放在不同文件夹下面,加快查询速度。
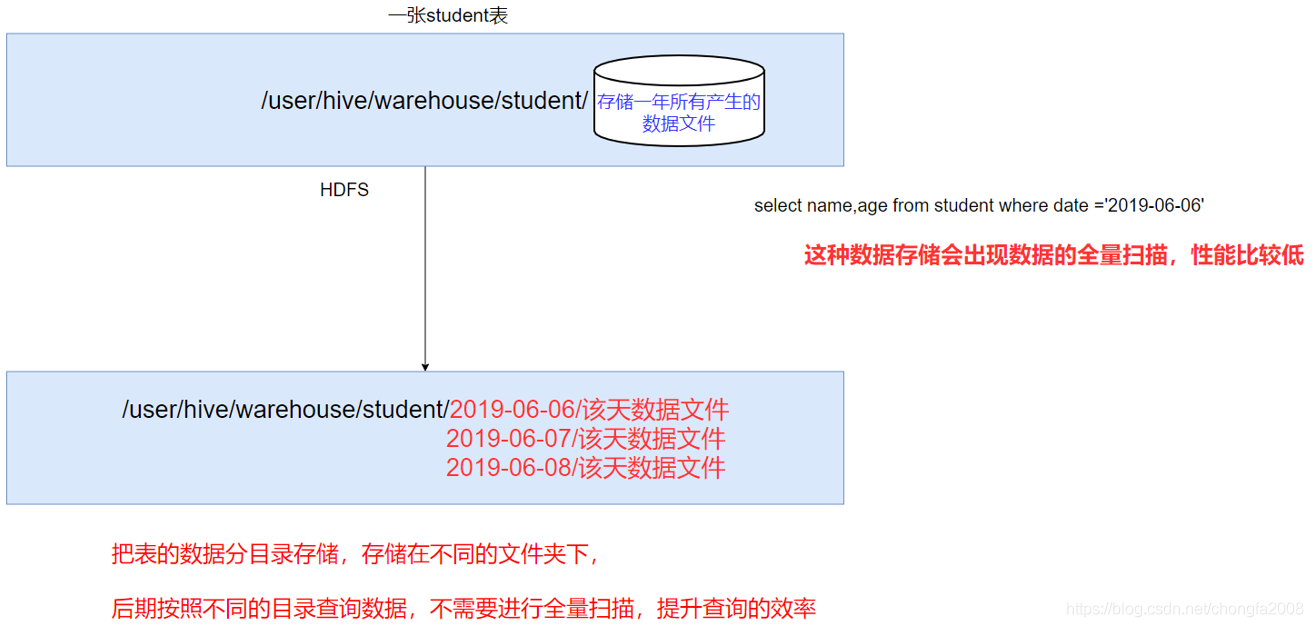
3:分区表相关语法
1:创建分区表语法
hive (myhive)> create table score(s_id string, c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by '\t';
2:创建一个表带多个分区
hive (myhive)> create table score2 (s_id string,c_id string, s_score int) partitioned by (year string, month string, day string) row format delimited fields terminated by '\t';
3:加载数据到分区表当中去
hive (myhive)>load data local inpath '/install/hivedatas/score.csv' into table score partition (month='201806');
4:加载数据到多分区表当中去
hive (myhive)> load data local inpath '/install/hivedatas/score.csv' into table score2 partition(year='2018', month='06', day='01');
5:查看分区
hive (myhive)> show partitions score;
6:添加一个分区
hive (myhive)> alter table score add partition(month='201805');
7:同时添加多个分区
注意:添加分区之后就可以在hdfs文件系统当中看到表下面多了一个文件夹
hive (myhive)> alter table score add partition(month='201804') partition(month = '201803');
8:删除分区
hive (myhive)> alter table score drop partition(month = '201806');
4:分区表实战
1:需求
现在有一个文件score.csv文件,里面有三个字段,分别是s_id string, c_id string, s_score int
字段都是使用 \t进行分割
存放在集群的这个目录下/scoredatas/day=20180607,这个文件每天都会生成,存放到对应的日期文件夹下面去
文件别人也需要公用,不能移动
请创建hive对应的表,并将数据加载到表中,进行数据统计分析,且删除表之后,数据不能删除
2:实现
1:数据准备
2:node03执行以下命令,将数据上传到hdfs上面去
将我们的score.csv上传到node03服务器的/install/hivedatas目录下,然后将score.csv文件上传到HDFS的/scoredatas/day=20180607目录上
cd /install/hivedatas/
hdfs dfs -mkdir -p /scoredatas/day=20180607
hdfs dfs -put score.csv /scoredatas/day=20180607/
3:创建外部分区表,并指定文件数据存放目录
hive (myhive)> create external table score4(s_id string, c_id string, s_score int) partitioned by (day string) row format delimited fields terminated by '\t' location '/scoredatas';
4:进行表的修复,说白了就是建立我们表与我们数据文件之间的一个关系映射()
hive (myhive)> msck repair table score4;
5:修复成功之后即可看到数据已经全部加载到表当中去了
我是小职,记得找我
✅ 解锁高薪工作
✅ 免费获取基础课程·答疑解惑·职业测评

 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式AI+学习就业服务平台 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 资料领取
资料领取

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




