

-


大数据云计算
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 小职
2021-09-14
来源 :浪尖聊大数据
阅读 833
评论 0
小职
2021-09-14
来源 :浪尖聊大数据
阅读 833
评论 0
摘要:本篇主要介绍了大数据开发--Hbase源码系列之regionserver应答数据请求服务设计,通过具体的内容展现,希望对于大家大数据的学习有一定的帮助。
本篇主要介绍了大数据开发--Hbase源码系列之regionserver应答数据请求服务设计,通过具体的内容展现,希望对于大家大数据的学习有一定的帮助。

一,基本介绍
Hbase源码系列主要是以hbase-1.0.0为例讲解hbase源码。本文主要是将Regionserver服务端RPC的结构及处理流程。希望是帮助大家彻底了解hbase Regionserver的内部结构。
本文会涉及Regionserver端接受客户端链接,处理读事件,交由调度器去执行,然后由Responder将结果返回给客户端整个过程。
建议大家多读读浪尖前面关于JAVA网络IO模型相关文章<JAVA的网络IO模型彻底讲解>和kafka的<Kafka源码系列之Broker的IO服务及业务处理>两篇文章,对大家设计服务端会有很大的帮助。
二,重要类
1,RSRpcServices
Regionserver的rpc服务的实现类
2,RpcServer
Regionserver处理的重要类。包括以下几个角色:
Listener
Responder
Reader
rpcScheduler
3,SimpleRpcSchedulerFactory
SimpleRPCScheduler的工厂类。
4,SimpleRpcScheduler
RegionServer的默认调度类,是可以配置的。包括三个优先级的线程池:general(普通表读写),高优先级(系统表),副本同步。
每个优先级的调度器又有不同的实现:
普通的调度器实现,可以有三种:
A),FastPathBalancedQueueRpcExecutor
B),RWQueueRpcExecutor
C),BalancedQueueRpcExecutor
对于副本同步及高优先级的只有一种实现
FastPathBalancedQueueRPCExecutor
总的等级有以下几种
normal_QOS < QOS_threshold < replication_QOS < replay_QOS < admin_QOS < high_QOS
分配策略是
public boolean dispatch(CallRunner callTask) throws InterruptedException {
// normal_QOS < QOS_threshold < replication_QOS < replay_QOS < admin_QOS < high_QOS
RpcServer.Call call = callTask.getCall(); //MultiServerCallable
int level = priority.getPriority(call.getHeader(), call.param, call.getRequestUser());
if (priorityExecutor != null && level > highPriorityLevel) {
return priorityExecutor.dispatch(callTask);
} else if (replicationExecutor != null && level == HConstants.REPLICATION_QOS) {
return replicationExecutor.dispatch(callTask);
} else {
return callExecutor.dispatch(callTask);
}
}
优先级对应的数值如下
public static final int NORMAL_QOS = 0;
public static final int QOS_THRESHOLD = 10; //highPriorityLevel
public static final int HIGH_QOS = 200;
public static final int REPLICATION_QOS = 5;
public static final int REPLAY_QOS = 6;
public static final int ADMIN_QOS = 100;
public static final int SYSTEMTABLE_QOS = HIGH_QOS;
5,Listener
一个Listener包含了一个固定数目的Reader,在一个固定线程数的ExecutorPool中运行,默认是10。
Listener主要负责监听accept事件,然后轮训获取一个Reader去做读事件。
6,Reader
每个Reader都有一个Selector,负责读取消息,然后封装成call,再将call封装成CallRunner,交给Scheduler去执行。然后Reader继续去遍历处理读事件。
7,Responder
在CallRunner#run 执行call结束之后,会让call将自身加入一个队列里,有Responder获取并应答客户端。
每个Regionserver只会有一个Responder。
三,相关源码
1,调度器初始化过程
通过反射得到了SimpleRPCSchedulerFactory。
Class<?> rpcSchedulerFactoryClass = rs.conf.getClass(
REGION_SERVER_RPC_SCHEDULER_FACTORY_CLASS,
SimpleRpcSchedulerFactory.class);
rpcSchedulerFactory = ((RpcSchedulerFactory) rpcSchedulerFactoryClass.newInstance());
然后在创建RpcServer的时候,创建了SimpleRPCScheduler。
rpcServer = new RpcServer(rs, name, getServices(),
bindAddress, // use final bindAddress for this server.
rs.conf,
rpcSchedulerFactory.create(rs.conf, this, rs));
Create方法中,重点指定了三种调度器的线程数目
public RpcScheduler create(Configuration conf, PriorityFunction priority, Abortable server) {
int handlerCount = conf.getInt(HConstants.REGION_SERVER_HANDLER_COUNT,
HConstants.DEFAULT_REGION_SERVER_HANDLER_COUNT);
return new SimpleRpcScheduler(
conf,
handlerCount,
conf.getInt(HConstants.REGION_SERVER_HIGH_PRIORITY_HANDLER_COUNT,
HConstants.DEFAULT_REGION_SERVER_HIGH_PRIORITY_HANDLER_COUNT),
conf.getInt(HConstants.REGION_SERVER_REPLICATION_HANDLER_COUNT,
HConstants.DEFAULT_REGION_SERVER_REPLICATION_HANDLER_COUNT),
priority,
server,
HConstants.QOS_THRESHOLD);
}
2,Listener的初始化过程
在RSRpcServices的start方法中,调用了RpcServer的start,然后启动了listener.start()
具体的初始化是在Listener的构造函数中做的
super(name);
backlogLength = conf.getInt("hbase.ipc.server.listen.queue.size", 128);
// Create a new server socket and set to non blocking mode
acceptChannel = ServerSocketChannel.open();
acceptChannel.configureBlocking(false);
// Bind the server socket to the binding addrees (can be different from the default interface)
bind(acceptChannel.socket(), bindAddress, backlogLength);
port = acceptChannel.socket().getLocalPort(); //Could be an ephemeral port
// create a selector;
selector= Selector.open();
readers = new Reader[readThreads];
readPool = Executors.newFixedThreadPool(readThreads,
new ThreadFactoryBuilder().setNameFormat(
"RpcServer.reader=%d,bindAddress=" + bindAddress.getHostName() +
",port=" + port).setDaemon(true)
.setUncaughtExceptionHandler(Threads.LOGGING_EXCEPTION_HANDLER).build());
for (int i = 0; i < readThreads; ++i) {
Reader reader = new Reader();
readers[i] = reader;
readPool.execute(reader);
}
LOG.info(getName() + ": started " + readThreads + " reader(s) listening on port=" + port);
// Register accepts on the server socket with the selector.
acceptChannel.register(selector, SelectionKey.OP_ACCEPT);
this.setName("RpcServer.listener,port=" + port);
this.setDaemon(true);
当监听到有接收事件之后,轮询取出一个Reader,将Channel注册到该reader的Selector上由该Reader监听读事件。
Reader getReader() {
currentReader = (currentReader + 1) % readers.length;
return readers[currentReader];
}
注册
reader.startAdd();
SelectionKey readKey = reader.registerChannel(channel);
c = getConnection(channel, System.currentTimeMillis());
readKey.attach(c);
3,Reader的初始化过程及处理过程
Reader是在Listener构建的时候初始化并加到线程池中执行的。
readers = new Reader[readThreads];
readPool = Executors.newFixedThreadPool(readThreads,
new ThreadFactoryBuilder().setNameFormat(
"RpcServer.reader=%d,bindAddress=" + bindAddress.getHostName() +
",port=" + port).setDaemon(true)
.setUncaughtExceptionHandler(Threads.LOGGING_EXCEPTION_HANDLER).build());
for (int i = 0; i < readThreads; ++i) {
Reader reader = new Reader();
readers[i] = reader;
readPool.execute(reader);
}
Reader的数目由,控制。
"hbase.ipc.server.read.threadpool.size", 10
Reader的具体处理,主要是经过Reader处理之后交给了调度器去执行。
实际上最终是在Connection的processRequest方法中交给调度器执行的
if (!scheduler.dispatch(new CallRunner(RpcServer.this, call))) {
callQueueSize.add(-1 * call.getSize());
ByteArrayOutputStream responseBuffer = new ByteArrayOutputStream();
metrics.exception(CALL_QUEUE_TOO_BIG_EXCEPTION);
setupResponse(responseBuffer, call, CALL_QUEUE_TOO_BIG_EXCEPTION,
"Call queue is full on " + server.getServerName() +
", too many items queued ?");
responder.doRespond(call);
}
调度器分配的策略
public boolean dispatch(CallRunner callTask) throws InterruptedException {
// normal_QOS < QOS_threshold < replication_QOS < replay_QOS < admin_QOS < high_QOS
RpcServer.Call call = callTask.getCall(); //MultiServerCallable
int level = priority.getPriority(call.getHeader(), call.param, call.getRequestUser());
if (priorityExecutor != null && level > highPriorityLevel) {
return priorityExecutor.dispatch(callTask);
} else if (replicationExecutor != null && level == HConstants.REPLICATION_QOS) {
return replicationExecutor.dispatch(callTask);
} else {
return callExecutor.dispatch(callTask);
}
}
4,Responder应答的过程
在交给调度器执行后,会将call交给Responder,由其最终监听写事件,给客户端答复。
Responder线程是在构建RpcServer的时候初始化,start的时候start
在其run方法中,会循环调用
registerWrites();
然后执行具体写事件
Set<SelectionKey> keys = writeSelector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
try {
if (key.isValid() && key.isWritable()) {
doAsyncWrite(key);
}
} catch (IOException e) {
LOG.debug(getName() + ": asyncWrite", e);
}
}
四,总结
根据源码,我画出了Regionserver的服务端请求处理图,也可以叫Regionserver的Rpc结构图。如下:
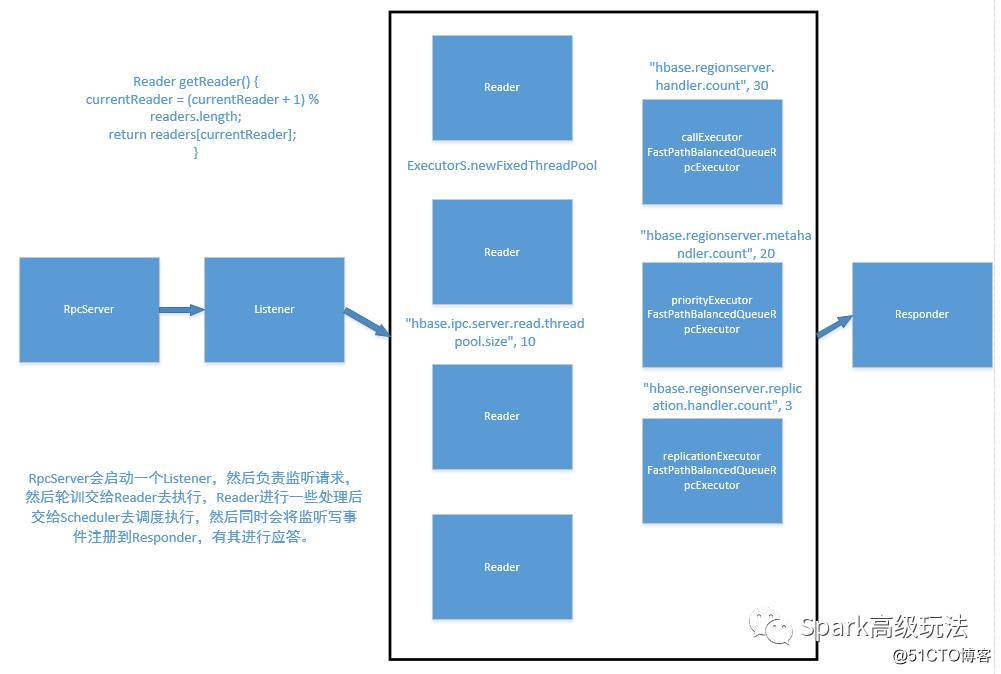
Hbase源码系列之regionserver应答数据请求服务设计_Spark
从图中我们可以总结出一下几点:
1,这个也是经典的Rector多线程模型(变动是会将应答汇聚到一个线程)。
2,一个线程负责接收事件监听客户端链接请求。
3,多个线程负责处理客户端请求。
4,有具体的业务逻辑执行交由调度器去执行客户端的请求(默认是,普通表,副本请求,系统表三种级别线程池)。
5,一个线程负责应答。
可以对比浪尖前面<Kafka源码系列之Broker的IO服务及业务处理>就可以看出二者的不同。
Kafka的Broker是IO线程和业务线程分离,均是多线程,应答也是交由IO线程组做的。而hbase的regionserver是将IO线程进行了读写分离,读线程是多线程,而写(应答线程)是单线程来做的。
IO请求处理方面来说kafka是很优秀的优的,但是hbase regionserver的调度器实现了按等级分离线程池模型,保证更优先级的操作能执行这个特点也比较不错。会发现某些管理操作阻塞,但是读写正常,这个我遇到过。这就体现了它优势。
我是小职,记得找我
✅ 解锁高薪工作
✅ 免费获取基础课程·答疑解惑·职业测评

 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




