

-


大数据云计算
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 小职
2021-08-24
来源 :Lansonli
阅读 1014
评论 0
小职
2021-08-24
来源 :Lansonli
阅读 1014
评论 0
摘要:本文主要是介绍了大数据Kafka:Kafka的集群搭建以及shell启动命令脚本编写,通过具体的内容向大家展现,希望对大家大数据Kafka的学习有所帮助。
本文主要是介绍了大数据Kafka:Kafka的集群搭建以及shell启动命令脚本编写,通过具体的内容向大家展现,希望对大家大数据Kafka的学习有所帮助。

Kafka的集群搭建以及shell启动命令脚本编写
一、搭建Kafka集群
1、 将Kafka的安装包上传到虚拟机,并解压
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
cd /export/server/kafka_2.12-2.4.1/
2、修改 server.properties
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node1:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181
3、将安装好的kafka复制到另外两台服务器
cd /export/server
scp -r kafka_2.12-2.4.1/ node2:$PWD
scp -r kafka_2.12-2.4.1/ node3:$PWD
修改另外两个节点的broker.id分别为1和2
---------node2--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=1
listeners=PLAINTEXT://node2:9092
--------node3--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=2
listeners=PLAINTEXT://node3:9092
4、配置KAFKA_HOME环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME}
分发到各个节点
scp /etc/profile node2:$PWD
scp /etc/profile node3:$PWD
每个节点加载环境变量
source /etc/profile
5、启动服务器
# 启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
# 测试Kafka集群是否启动成功 :
使用 jps 查看各个节点 是否出现有kafka
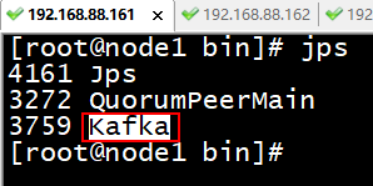
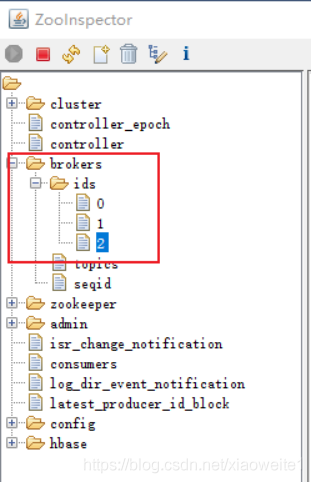
或者通过 zookeeper查看 brokers节点目录下, 是否有三个ids
二、目录结构分析

三、Kafka一键启动/关闭脚本
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作。将来只要执行一次该脚本就可以快速启动/关闭Kafka。
1、在节点1中创建 /export/onekey 目录
cd /export/onekey
2、准备slave配置文件,用于保存要启动哪几个节点上的kafka
node1
node2
node3
3、编写start-kafka.sh脚本
vim start-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup ${KAFKA_HOME}/bin/kafka-server-start.sh ${KAFKA_HOME}/config/server.properties >/dev/nul* 2>&1 & "
}&
wait
done
4、编写stop-kafka.sh脚本
vim stop-kafka.sh
cat /export/onekey/slave | while read line
do
{
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
}&
wait
done
5、给start-kafka.sh、stop-kafka.sh配置执行权限
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh
6、执行一键启动、一键关闭
./start-kafka.sh
./stop-kafka.sh
我是小职,记得找我
✅ 解锁高薪工作
✅ 免费获取基础课程·答疑解惑·职业测评

 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




