大数据Kafka:Kafka特点总结和架构
摘要:本文主要是介绍了大数据Kafka:Kafka特点总结和架构,通过具体的内容向大家展现,希望对大家大数据Kafka的学习有所帮助。
本文主要是介绍了大数据Kafka:Kafka特点总结和架构,通过具体的内容向大家展现,希望对大家大数据Kafka的学习有所帮助。

目录
一、Kafka特点总结
kafka特点总结
二、Kafka架构
架构图
专业术语
一、Kafka特点总结
kafka是大数据中一款消息队列的中间件产品, 最早是有领英开发的, 后期将其贡献给了apache 成为apache的顶级项目
kafka是采用Scala语言编写 kafka并不是对JMS规范完整实现 仅实现一部分 , kafka集群依赖于zookeeper
kafka可以对接离线业务或者实时业务, 可以很好的和apache其他的软件进行集成, 可以做流式数据分析(实时分析)
kafka特点总结
高可靠性 : 数据不容易丢失, 数据分布式存储, 集群某个节点宕机也不会影响
高可扩展性 : 动态的进行添加或者减少集群的节点
高耐用性 : 数据持久化的磁盘上
高性能 : 数据具有高吞吐量
非常快: 零停机和零数据丢失 (存在重复消费问题)
二、Kafka架构
架构图
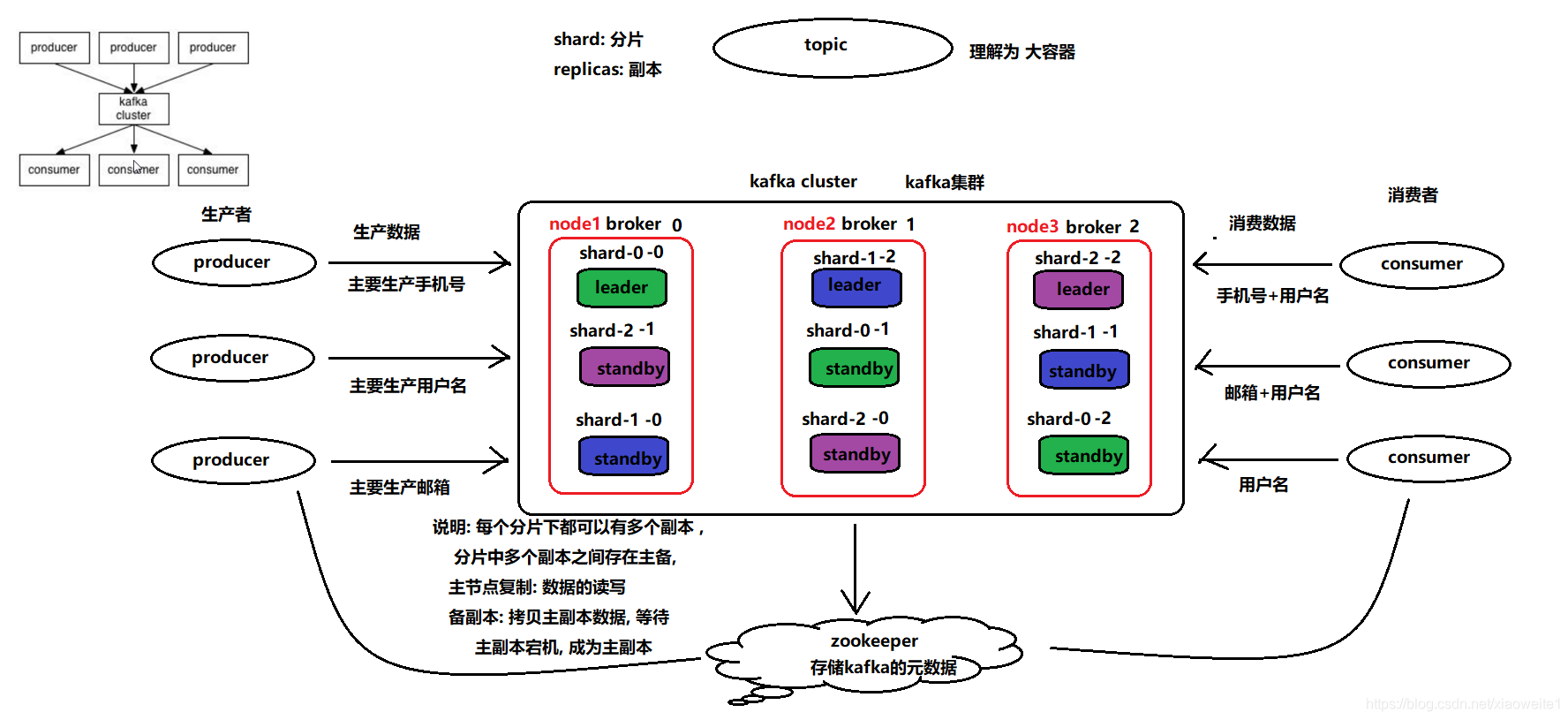
专业术语
kafka cluster: kafka的集群
broker: kafka集群中各个节点
producer: 生产者
consumer: 消费者
topic: 主题 话题 类似于大的容器
shard: 分片 类似于将大的容器切分为多个小的容器分片数量是否受限于集群节点数量呢? 不会的
replicas: 副本 对每个分片构建多个副本, 保证数据不丢失副本数量是否会受限于集群节点的数据呢? 是 最多和节点是一致的
我是小职,记得找我
✅ 解锁高薪工作
✅ 免费获取基础课程·答疑解惑·职业测评



0 不喜欢
0
看完这篇文章有何感觉?
已经有0人表态,0%的人喜欢




