

-


大数据云计算
站-
热门城市 全国站>
-
其他省市
-
-

 15692118659
15692118659
 小职
2020-12-09
来源 :Alice菌https://juejin.cn/post/6897833801989390343
阅读 1613
评论 0
小职
2020-12-09
来源 :Alice菌https://juejin.cn/post/6897833801989390343
阅读 1613
评论 0
摘要:本篇文章,主要分享一下从中学习到的关于Hive命令的7个小技巧,希望对大数据的学习会有所帮助。
本篇文章,主要分享一下从中学习到的关于Hive命令的7个小技巧,希望对大数据的学习会有所帮助。

Hive命令说明
在Hive提供的所有连接方式中,命令行界面是最常用的一种方式。用户可以使用Hive的命令行对Hive中的数据库、数据表和数据进行各种操作。
1、Hive命令选项
在服务器上启动Hadoop之后,输入“Hive”命令就能够进入Hive的命令行。也可以输入如下命令查看Hive的命令选项:
hive --help
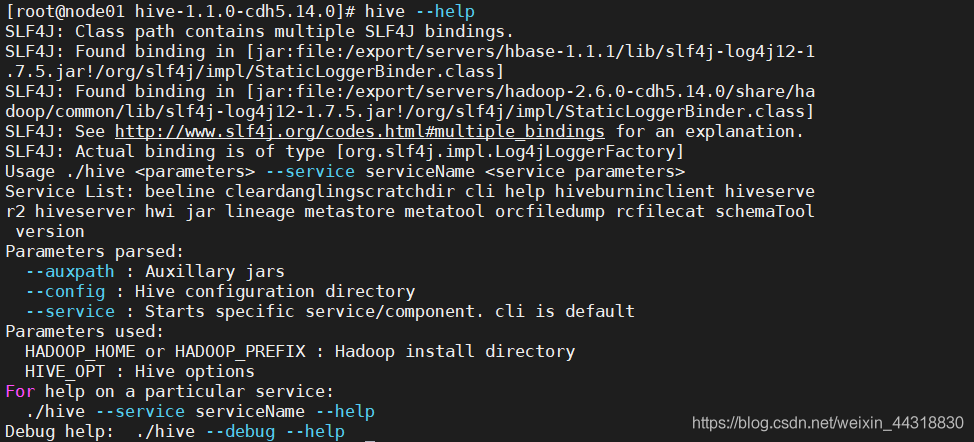
可以看到,输出了Hive的一些命令选项,说明用户可以通过 --service serviceName的方式启动某个服务。以下信息列出了Hive主要的命令行选项:

其中,部分重要选项的说明如下:
(1) cli:命令行界面
(2)hiveserver2:启动Hive远程模式时需要启动的服务,其可以监听来自其他进程的连接
(3)jar:扩展自 hadoop jar 命令,可以执行需要 Hive 环境的应用程序
(4)metastore:启动一个 Hive 元数据服务
接下来,在CentOS6.8服务器的命令行中输入如下命令,查看Hive的CLI选项:
hive --help --service cli
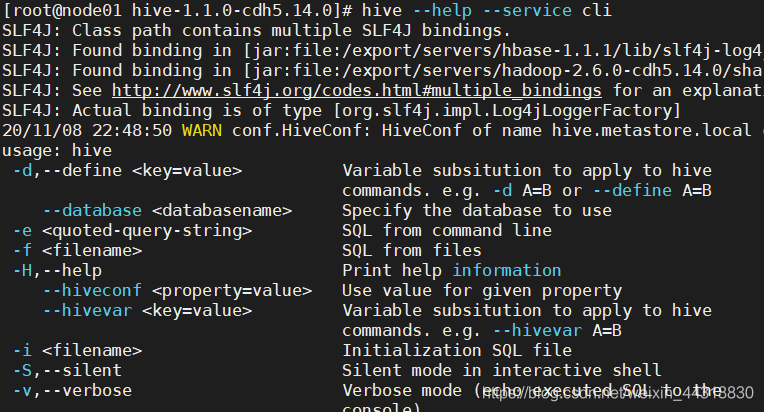
选项说明如下:
(1)-d,--define
(2) --databases:指定使用的数据库名称
(3) -e:从服务器命令行执行SQL语句
(4) -f :从文件中执行SQL语句
(5) -H:--help :输出帮助信息
(6) --hiveconf
(7) --hivevar
(8) -i :初始化SQL文件
(9) -S,-- silent:集成模式下开启静默模式
(10) -v,-- verbose:输出详细信息
2、Hive命令的使用
在命令行输入“hive”命令,即可进入Hive命令行终端,如下所示:
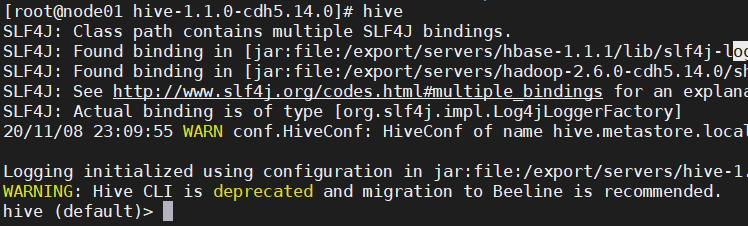
我们写个查询语句
hive (default)> select * from testdb.student;
OK
student.s_id student.s_name student.s_birth student.s_sex
01 永昌 1990-01-01 男
02 鸿哲 1990-12-21 男
03 文景 1990-05-20 男
04 李云 1990-08-06 男
05 妙之 1991-12-01 女
06 雪卉 1992-03-01 女
07 秋香 1989-07-01 女
08 王丽 1990-01-20 女
Time taken: 1.197 seconds, Fetched: 8 row(s)
复制代码
很多时候,执行一条查询语句并不需要打开命令行界面。此时可以使用“hive -e”形式的命令,如下所示:
[root@node01 hive-1.1.0-cdh5.14.0]# hive -e "select count(*) from testdb.student"
Logging initialized using configuration in jar:file:/export/servers/hive-1.1.0-cdh5.14.0/lib/hive-common-1.1.0-cdh5.14.0.jar!/hive-log4j.properties
Query ID = root_20201108231818_becc7952-05a5-49fc-915d-b6648d429f08
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1604845856822_0001, Tracking URL = //node01:8088/proxy/application_1604845856822_0001/
Kill Command = /export/servers/hadoop-2.6.0-cdh5.14.0/bin/hadoop job -kill job_1604845856822_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-11-08 23:18:36,501 Stage-1 map = 0%, reduce = 0%
2020-11-08 23:18:37,649 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.88 sec
2020-11-08 23:18:38,739 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.18 sec
MapReduce Total cumulative CPU time: 2 seconds 180 msec
Ended Job = job_1604845856822_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.18 sec HDFS Read: 11544 HDFS Write: 580032 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 180 msec
OK
_c0
8
复制代码
如果不需要输出过多的日志信息,则可以在 hive 后面加 -S 选项,如下所示:
[root@node01 hive-1.1.0-cdh5.14.0]# hive -S -e "select count(*) from testdb.student"
_c0
8
复制代码
如果需要一次性执行多条语句,可以将多条语句保存到以 .hql 结尾的文件中,如下所示:
vim test.sql
select count(*) from testdb.student;
select * from testdb.student;
复制代码
使用hive -f命令来执行 hql 文件中的语句,如下所示:
[root@node01 tmpfile]# hive -f test.sql
_c0
8
Time taken: 11.551 seconds, Fetched: 1 row(s)
OK
student.s_id student.s_name student.s_birth student.s_sex
01 永昌 1990-01-01 男
02 鸿哲 1990-12-21 男
03 文景 1990-05-20 男
04 李云 1990-08-06 男
05 妙之 1991-12-01 女
06 雪卉 1992-03-01 女
07 秋香 1989-07-01 女
08 王丽 1990-01-20 女
Time taken: 0.071 seconds, Fetched: 8 row(s)
复制代码
可以用“--”添加注释,如下所示:
hive (default)> select * from testdb.student -- 测试查询数据;
OK
student.s_id student.s_name student.s_birth student.s_sex
01 永昌 1990-01-01 男
02 鸿哲 1990-12-21 男
03 文景 1990-05-20 男
04 李云 1990-08-06 男
05 妙之 1991-12-01 女
06 雪卉 1992-03-01 女
07 秋香 1989-07-01 女
08 王丽 1990-01-20 女
Time taken: 0.073 seconds, Fetched: 8 row(s)
复制代码
3、hiverc文件
在${HIVE_HOME}/bin目录下有个.hiverc文件,它是隐藏文件,我们可以用Linux的ls -a命令查看。我们在启动Hive的时候会去加载这个文件中的内容,所以我们可以在这个文件中配置一些常用的参数,如下:
cd /export/servers/hive-1.1.0-cdh5.14.0/bin
vim .hiverc
select * from testdb.student;
set hive.cli.print.current.db=true;
#查询出来的结果显示列的名称
set hive.cli.print.header=true;
#启用桶表
set hive.enforce.bucketing=true;
#压缩hive的中间结果
set hive.exec.compress.intermediate=true;
#对map端输出的内容使用BZip2编码/解码器
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#压缩hive的输出
set hive.exec.compress.output=true;
#对hive中的MR输出内容使用BZip2编码/解码器
set mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#让hive尽量尝试local模式查询而不是mapred方式
set hive.exec.mode.local.auto=true;
复制代码
例如,我们这里在.hiverc文件中添加了一句HQL查询语句,那么每次我们启动hive命令行,都会自动去执行这个命令。
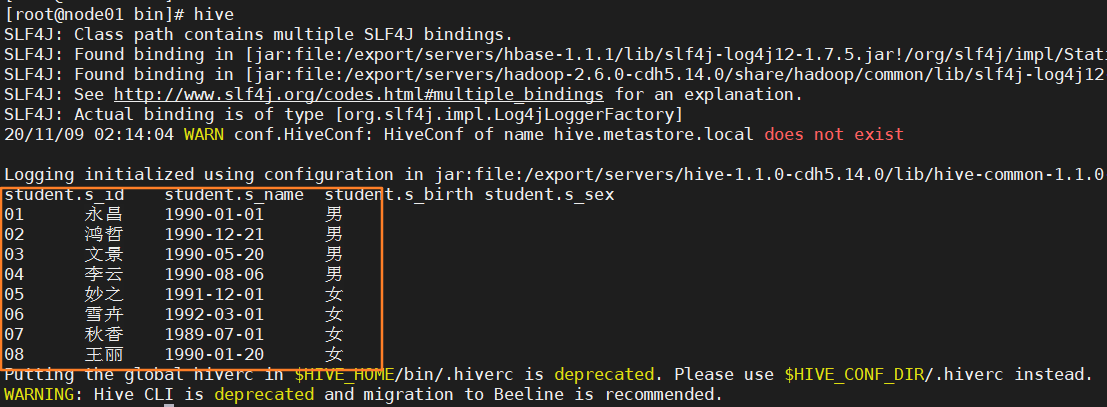
可以看到,输入“hive”命令启动 Hive 命令行,自动执行了 .hiverc 文件中的语句。
当我们需要频繁使用某些命令时,就可以将这些命令保存在.hiverc文件中。
4、Hive操作命令历史
Hive将最近执行的 10000 条命令记录到当前用户的 home 目录下的.hivehistory文件中,用户可以输入如下命令查看这个文件(当前用户为root):
cat vim /root/.hivehistory
5、在Hive命令行执行系统命令
在Hive命令行下执行操作系统命令非常简单,只需要在执行的系统命令前加上“!”,并以“;”结尾即可,如下所示:
hive (default)> !echo "hello world";
"hello world"
hive (default)> !jps;
11985 ResourceManager
18308 Jps
12420 RunJar
12085 NodeManager
12519 RunJar
11545 NameNode
18138 RunJar
11837 SecondaryNameNode
11646 DataNode
复制代码
6、在Hive命令行执行Hadoop命令
在Hive命令行可以执行 Hadoop 命令,只需要将 Hadoop 命令中的关键字 hdfs 去掉,最后添加一个“;”即可。
例如,在操作系统命令行执行 Hadoop 的如下命令:
[root@node01 ~]# hdfs dfs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2020-01-03 02:28 /aa
drwxr-xr-x - PC supergroup 0 2020-03-30 10:33 /aaa
drwxr-xr-x - root supergroup 0 2019-12-27 05:42 /abc
复制代码
在Hive命令行执行 Hadoop 命令,如下所示:
hive (default) > dfs -ls /;
Found 3 items
drwxr-xr-x - root supergroup 0 2020-01-03 02:28 /aa
drwxr-xr-x - PC supergroup 0 2020-03-30 10:33 /aaa
drwxr-xr-x - root supergroup 0 2019-12-27 05:42 /abc
复制代码
可以看到,得出的结果是一致的。
7、在 Hive 命令行显示查询字段名
使用 Hive 命令查询数据时,可以显示查询数据的字段名称,此时需要将 Hive 的 hive.cli.print.header 属性设置为 true,默认为 false,如下所示:
hive (default)> set hive.cli.print.header=true;
hive (default)> select * from testdb.student;
OK
student.s_id student.s_name student.s_birth student.s_sex
01 永昌 1990-01-01 男
02 鸿哲 1990-12-21 男
03 文景 1990-05-20 男
04 李云 1990-08-06 男
05 妙之 1991-12-01 女
06 雪卉 1992-03-01 女
07 秋香 1989-07-01 女
08 王丽 1990-01-20 女
Time taken: 0.056 seconds, Fetched: 8 row(s)
复制代码
小结
本篇文章主要分享了关于Hive的7个小技巧,希望本篇在您大数据学习的过程中有所帮助。
关注“职坐标在线”(Zhizuobiao_Online)公众号,免费获取源码资料、技术就业咨询。

 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-IT技术咨询与就业发展一体化服务 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




